spaCy Workbench is a python program that provides a user friendly interface to the spaCy NLP (Natural Language Processing) library. spaCy is a machine learning system that trains models to understand the linguistic aspects of a language. Pre-trained models are available for many languages. spaCy Workbench allows the novice to use spaCy without any skills in programming, machine learning or AI.
The spaCy Workbench program presented in this post provides a user interface that allows you to see what spaCy can do without any programing involved (how’s that for easy). Because it’s Python you can run the code on Windows, Mac, or Unix. The source code for spaCy NLP Workbench provides solid example code that you can use in your own projects. This post is part of my spaCy Python Tutorial.
I’m in the early phases of this effort so the current functionality is pretty basic. This is part of a larger effort to build a complete pipeline from spoken words to knowledge graphs. You can read more about this here.
What Does spaCy Workbench Do?
sPacy Workbench provides a graphical user interface that runs the spaCy NLP functionality. spaCy takes in raw text and produces a “document” object. The document object contains a linguistic analysis of the text based on a trained language “model”. For a quick overview of how spaCy works see here. sPacy Workbench does all the work and displays the results.
The Workbench File
The workbench file allows you to save the text file and language model making it easy to save and open different texts you are working on.
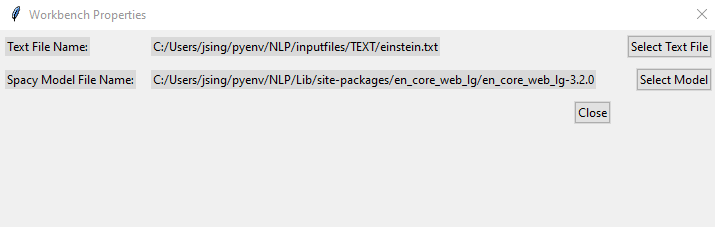
There are two properties that define a spaCy Workbench.
- Text File Name: this is the text file that you want spaCy to analyze
- spaCy Model Folder: this is the folder that contains the trained language model
Raw Text
This is the actual text contained in the text file. The example below is from a Wikipedia page about Albert Einstein. Rather than loading a text file, you can just type a sentence here.

Sentences
One of the first things spaCy does is divide the text into sentences. It does this using punctuation and a linguistic analysis of the text. This is called “Sentence Boundary Detection” or SBD.
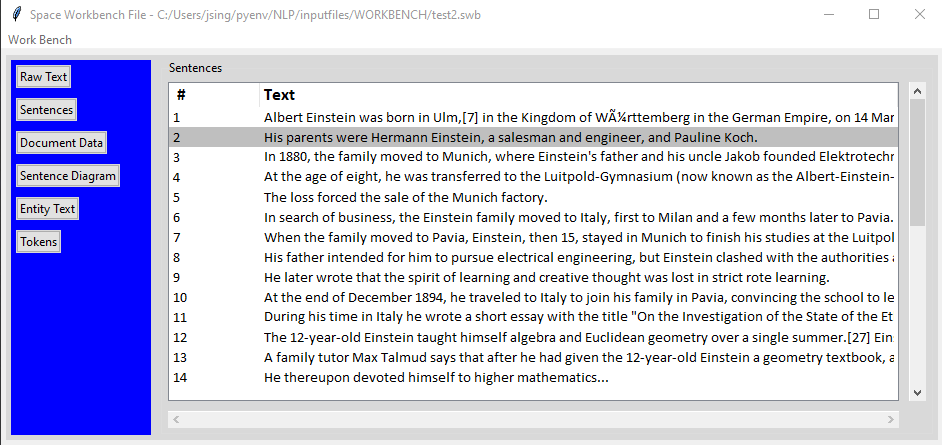
You can click on any sentence in the grid. This will determine which sentence is used on the Sentence Diagram tab and the Entity Text tab.
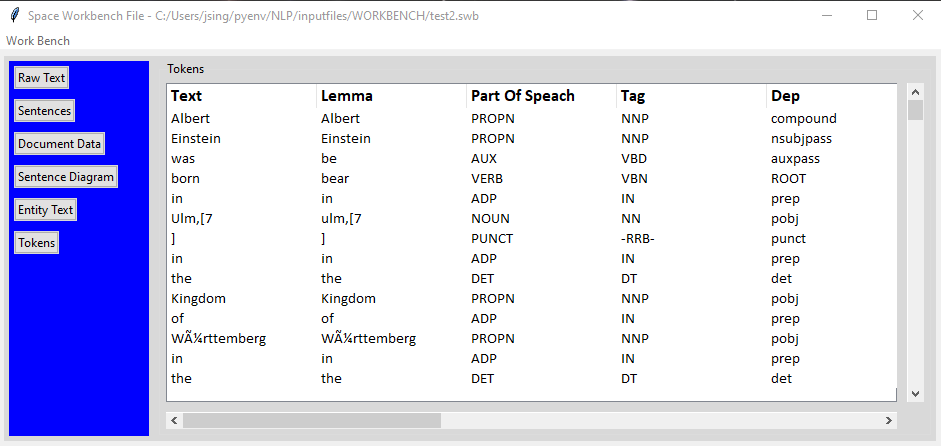
Tokens
The spaCy tokenizer splits the text into “tokens” essentially words and punctuation marks. It then performs different analysis of each token and how it is used in the sentence. The Tokens grid displays most of the attributes that are generated by this analysis. In the screen shot below you can see the part of speech property for each token.
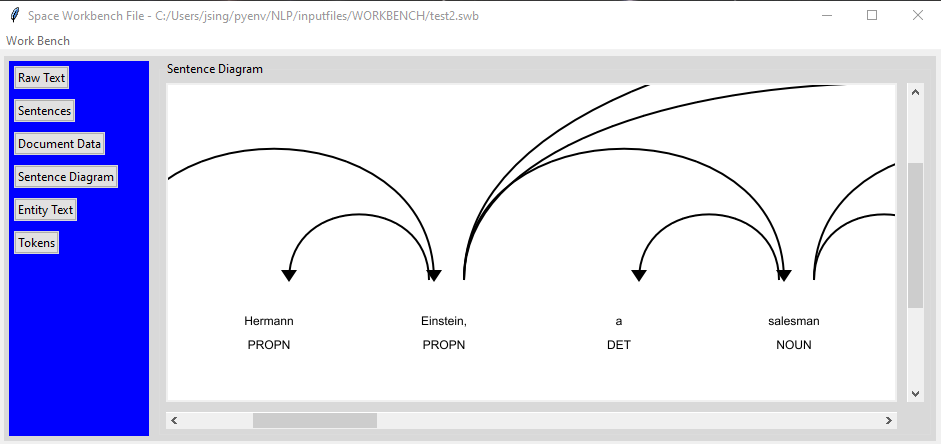
Sentence Diagram
The sentence diagram tab will display a diagram of the sentence that is selected in the “Sentences” tab. You can scroll around to see the entire diagram. This output is generated by the displaCy component.
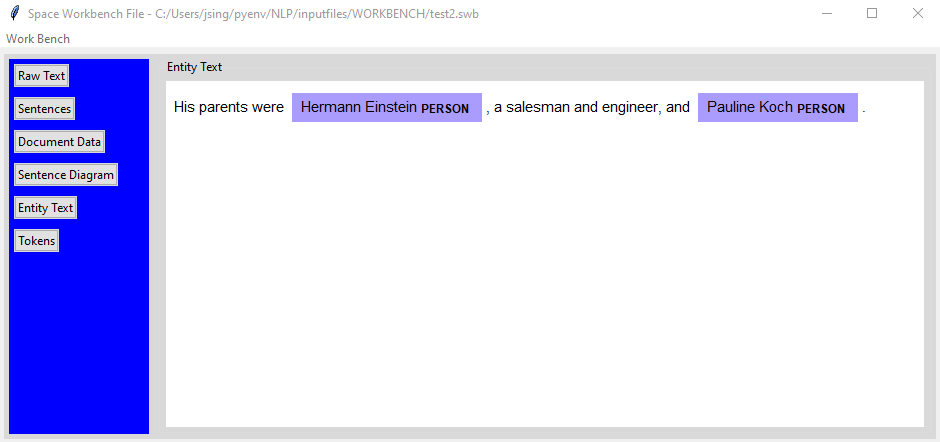
Annotated Entity Recognition
The “Entity Text” tab displays the sentence selected in the “Sentences” tab with colors and entity types. In the example below you can see the two names highlighted with the entity type “PERSON” next to them. spaCy identifies many types of entities out of the box and can be trained to do more.
How To Get The spaCy NLP Workbench Source Code
The source code for spaCy Workbench is on GitHub. You can download the Python code and run it on Windows, Mac, or Linux.
The spaCy NLP Workbench Python Setup
NLP Workbench is a Python program with a graphical user interface developed using Tkinter (the UI provided with Python). As such, this application will run on Windows, Mac, or Linux – basically anywhere Python runs.
This blog post describes the detailed instructions to setup the Python environment
And Finally…
Thanks for taking the time to look at the NLP Workbench. This is a great way to get a quick demo of what spaCy is capable of doing and some good example python code. Look at the detailed posts for specific description of the python code. Please leave a comment below if you have any suggestions for additional features.

