
There are a lot of services available that will transcribe your podcast audio file to text. The one problem is they all cost money – not that this is a bad thing – you should expect to pay for value received. But what if there is a free solution? Well if you have some Python skills and are willing to do some experimentation I’ve got a place for you to start. I have posted a series of articles with python scripts that will walk you through the process. You can work through them starting here.
Free Solution
If you’re looking for free audio to text transcription software you’ve come to the right place.
If you’re like me and just want a user friendly solution to how to transcribe a podcast to text for free then keep reading. I have developed a simple python gui application that you can download. It is open source and free to use. The actual hard work is done by the Vosk library which is based on Kaldi.
Installation
You have two choices for installing AudioText. The first choice is for people who have Python skills and want to work with the source code. The second choice is for people who just want to run the program (aka the easy way). Once you have AudioText installed you then have to download a language model from the VOSK website.
Easy Installation – WINDOWS ONLY
This is the best and easiest way to install and run AudioText. Simply download this zip file and extract the entire archive into a folder on your file system. The zip file is pretty big – this is mostly due to the fact that I’m using the ffmpeg library and the exe’s are large.
The folder you download is a complete (batteries included) python environment and python application with all the needed python libraries. This is nice as it won’t mess up any existing python installations you might have or if you know nothing about Python it does all the work for you. This “compiled” version of the AudioText python application was created using PyInstaller which you can read about here.
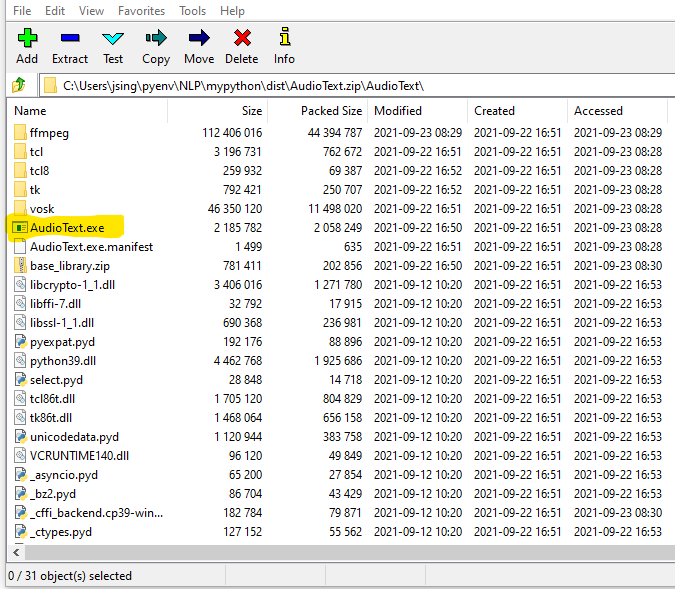
The screen shot below shows the directory structure. You can see the “AudioText.exe” file. This is the executable that will run the AudioText python appliication. This will only work on Windows. If you have a Linux or Mac system you will have to go the Python Installation (see below) route and build your own python environment.
Warning – The EXE is not code signed
The AudioText.exe file is not “code signed”. This means that Windows Defender will display a message warning you not to run the program. It will also provide a button for you to run it anyway. Your anti-virus may also object to running this exe. The only way for me to avoid this is to spend $400 dollars on a Windows code signing certificate which I’m not going to do. Sorry, but this is how Windows works. Apple is better and provides code signing certs when you pay the $95 a year fee to be an Apple Developer.
Finally – you have to download a language model – see below.
Python Installation
If you performed the Easy Installation above you do not need to do this step. This is for Python gearheads that want to work with the source code. Here are the steps:
- Create a python virtual environment using the instructions in this post. This is the environment used for the posts that illustrated the basic process using simple python scripts.
- Cut and paste the AudioText source code into a file in your virtual environment and give it a try. The entire application is contained in one python file – audiotext.py.
- Download and install a language model – see below.
Download A Language Model
The only thing not included in the installation is a “language model” which is provided by the VOSK website. You select a language model based on your needs – many languages are supported.
Vosk is the library that provides the actual speech to text translation software. You can read more about Vosk here.
- download a model from here. I downloaded “vosk-model-en-us-aspire-0.2” which is a large English language model. There are models for multiple languages available. They also have a small English model that you can run on a Raspberry Pi !
- unzip the downloaded model file to a folder named “model”. I put the model folder here… “C:\Users\xxx\pyenv\NLP\model”. The AudioText application will ask you for the path to the model folder so you can put the model anywhere you want.
How To Use AudioText
You need to identify two things before you can transcribe an audio file to a text transcript.
- Use the File menu at the top of the screen and select the language model path. This is the top level folder that contains the language model you downloaded from the Vosk website as a part of the setup process. The model path will appear on the screen.
- Use the File menu again to select the audio file you want to transcribe. This can be a WAV or an MP3 file.
Once you have completed the above tasks, you simply click on the “Convert To Text” button. The application will begin transcribing your audio file using the identified language model.
The following screen shot shows AudioText while it is running.
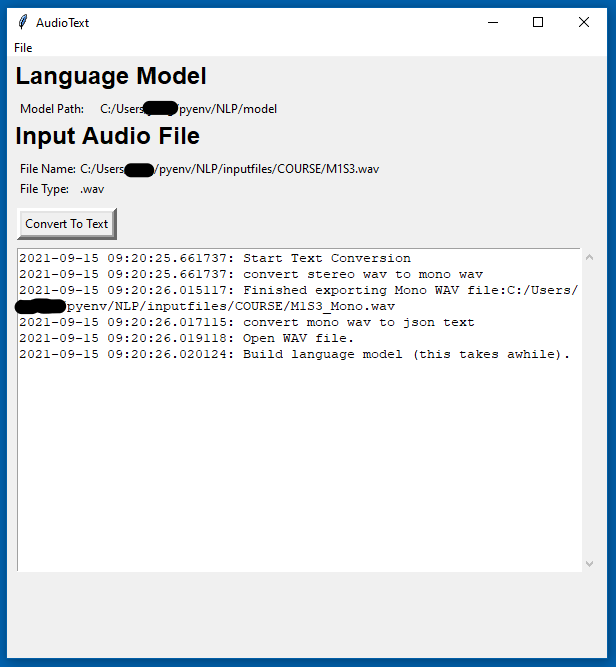
Notice the last line in the log – it tells you that the language model is being processed which will take a few minutes depending on it’s size. Once the program starts the transcribing process, the log will display each phrase as it is analyzed. On longer audio files however, the application will just sit (not responding) until it is completely finished at which point the entire log will display. A long audio file will take a long time to process.
Results of Audio to Text Conversion
The AudioText program produces several WAV files and two output JSON files which will be saved in the same directory as the input audio file. The files are:
- xxx_stereo.wav – if you start with an mp3 file the first thing AudioText does is convert it to a WAV file with two channels.
- xxx_Mono.wav – The next thing that happens is the stereo WAV file is converted to a mono WAV file. VOSK requires a single channel WAV file to process.
- xxx-Results.json – Finally, the applications processes the mono WAV file and produces a json file that contains each phrase and word with the starting and ending times for each word.
- xxx-Text.json – This is a simpler version of the output data with only the converted phrases. You can edit this in a text file or write a script to convert it to a document.
“xxx” above is your original audio file name. You can see the format of the JSON files here.
Source Code
Here is the full source code if you’d rather cut and paste this into your python environment. I described how to setup a python environment for all the code examples here.
'''
Copyright 2021 SingerLinks Consulting LLC
This file is part of AudioText.
AudioText is free software: you can redistribute it and/or modify
it under the terms of the GNU General Public License as published by
the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
AudioText is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License for more details.
You should have received a copy of the GNU General Public License
along with AudioText. If not, see <https://www.gnu.org/licenses/>.
'''
import os
from os import path
import datetime
from pydub import AudioSegment
import audioop
import wave
import json
from vosk import Model, KaldiRecognizer
import tkinter as tk
from tkinter import *
from tkinter import messagebox
from tkinter import filedialog as fd
class Window(Frame):
def __init__(self, master=None):
Frame.__init__(self, master)
self.master = master
self.audioPath = None
self.audioExt = None
# if running the compiled version then tell pydub where the ffmpeg exe is found.
if getattr(sys, 'frozen', False):
this_script_dir = path.dirname(path.realpath(__file__))
os.environ["PATH"] += os.pathsep + this_script_dir + '\\ffmpeg'
print(os.environ["PATH"])
# menu system
menu = Menu(self.master)
self.master.config(menu=menu)
fileMenu = Menu(menu)
fileMenu.add_command(label="Select Model Path", command=self.openModelPath)
fileMenu.add_command(label="Select Audio File", command=self.openAudioFile)
fileMenu.add_command(label="Exit", command=self.exitProgram)
menu.add_cascade(label="File", menu=fileMenu)
# model file controls
self.lbl3 = Label(self, text="Language Model", font= ('Helvetica', 18, 'bold'))
self.lbl3.place(x=5,y=0)
self.lbl4 = Label(self, text="Model Path:")
self.lbl4.place(x=10,y=40)
self.modelPath = tk.StringVar()
self.txtBoxPath = Label(self, textvariable = self.modelPath)
self.txtBoxPath.place(x=90, y = 40)
# input file controls
self.lbl0 = Label(self, text="Input Audio File", font= ('Helvetica', 18, 'bold'))
self.lbl0.place(x=5,y=60)
self.lbl1 = Label(self, text="File Name:")
self.lbl1.place(x=10,y=100)
self.audioFileName = tk.StringVar()
self.txtBoxName = Label(self, textvariable = self.audioFileName)
self.txtBoxName.place(x=70, y = 100)
self.lbl2 = Label(self, text="File Type:")
self.lbl2.place(x=10,y=120)
self.audioFileType = tk.StringVar()
self.txtBoxType = Label(self, textvariable = self.audioFileType)
self.txtBoxType.place(x=70, y = 120)
# buttons
self.btnConvertText = Button(root, text = 'Convert To Text', bd = '5', command = self.convertText)
self.btnConvertText.place(x=10, y=150)
# text area
self.frmTxt = Frame(root, height = 20, width = 70)
self.frmTxt.pack(side=LEFT)
self.frmTxt.place(x=10, y=190)
self.vsb = Scrollbar ( self.frmTxt, orient='vertical' )
self.vsb.pack( side = RIGHT, fill = Y )
self.txtLog = Text(self.frmTxt, height = 20, width = 70, yscrollcommand = self.vsb.set)
self.txtLog.pack(side=LEFT, fill=Y)
self.vsb.config( command = self.txtLog.yview )
# widget can take all window
self.pack(fill=BOTH, expand=1)
def exitProgram(self):
exit()
def openModelPath(self):
'select path to language model'
name= fd.askdirectory()
self.modelPath.set(name)
def openAudioFile(self):
'open audio file'
name= fd.askopenfilename(filetypes =[('Audio file', '*.wav *.mp3')])
self.audioFileName.set(name)
splitFile = os.path.splitext(name)
self.audioPath = splitFile[0]
self.audioExt = splitFile[1]
self.audioFileType.set(self.audioExt)
def logMsg(self, msg):
ct = datetime.datetime.now()
self.txtLog.insert(END, str(ct) + ": " + msg + "\n")
self.txtLog.see(END)
Tk.update_idletasks(self)
def clearLog(self):
self.txtLog.delete(0.0, END)
def convertText(self):
self.logMsg("Start Text Conversion")
self.clearLog()
self.processFiles()
self.logMsg("Text Conversion Processing Complete")
def processFiles(self):
'''
this method converts the audio file to text. This is a three step process:
1. convert mp3 file to wav file - this step is skipped if you start with a WAV file
2. convert wav file to mono file
3. process the mono wave file and write out json text files
'''
self.logMsg("Start Text Conversion")
if self.audioPath is None:
messagebox.showinfo("AudioText", "No audio file selected. File Select an Audio File.")
return
if self.modelPath.get() == "":
messagebox.showinfo("AudioText", "No model file selected. File Select a model path.")
return
# convert mp3 file to wav
if self.audioExt == '.mp3':
self.logMsg("convert mp3 to wav")
try:
# create file name for stereo wav file
self.wavStereoFile = self.audioPath + "_stereo.wav"
sound = AudioSegment.from_mp3(self.audioPath + self.audioExt)
# cut = sound[120 * 1000:180 * 1000]
# cut.export(self.wavStereoFile, format="wav")
sound.export(self.wavStereoFile, format="wav")
self.logMsg("Finished exporting WAV file:{}".format(self.wavStereoFile))
except Exception as e:
messagebox.showinfo("Error Converting MP3 To WAV", e)
return
# see if the user opened a wav file which skipped the mp3 to wav conversion step
if self.audioExt == '.wav':
self.wavStereoFile = self.audioFileName.get()
# if wav file is stereo then convert it to mono
self.logMsg("convert stereo wav to mono wav")
# read input file and write mono output file
try:
# open the input and output files
inFile = wave.open(self.wavStereoFile,'rb')
splitFile = os.path.splitext(self.wavStereoFile)
self.stereoPath = splitFile[0]
self.stereoExt = splitFile[1]
self.monoWav = self.stereoPath + "_Mono" + self.stereoExt
outFile = wave.open(self.monoWav,'wb')
# force mono
outFile.setnchannels(1)
# set output file like the input file
outFile.setsampwidth(inFile.getsampwidth())
outFile.setframerate(inFile.getframerate())
# read
soundBytes = inFile.readframes(inFile.getnframes())
print("frames read: {} length: {}".format(inFile.getnframes(),len(soundBytes)))
# convert to mono and write file
monoSoundBytes = audioop.tomono(soundBytes, inFile.getsampwidth(), 1, 1)
outFile.writeframes(monoSoundBytes)
self.logMsg("Finished exporting Mono WAV file:{}".format(self.monoWav))
except Exception as e:
messagebox.showinfo("Error Converting WAV stereo To WAV Mono", e)
return
finally:
inFile.close()
outFile.close()
# convert mono wav to text
try:
self.logMsg("convert mono wav to json text")
inFileName = self.monoWav
splitFile = os.path.splitext(inFileName)
self.jsonPath = splitFile[0]
outfileResults = self.jsonPath + "-Results.json"
outfileText = self.jsonPath + "-Text.json"
self.logMsg("Open WAV file.")
wf = wave.open(inFileName, "rb")
# initialize a str to hold results
results = []
textResults = []
# build the model and recognizer objects.
self.logMsg("Build language model (this takes awhile).")
model = Model(self.modelPath.get())
self.logMsg("Start recognizer.")
recognizer = KaldiRecognizer(model, wf.getframerate())
recognizer.SetWords(True)
self.logMsg("Process audio file.")
while True:
data = wf.readframes(4000)
if len(data) == 0:
break
if recognizer.AcceptWaveform(data):
recognizerResult = recognizer.Result()
# convert the recognizerResult string into a dictionary
resultDict = json.loads(recognizerResult)
# save the entire dictionary in the list
results.append(resultDict)
# save the 'text' value from the dictionary into a list
textResults.append(resultDict.get("text", ""))
self.logMsg(resultDict.get("text", ""))
# process "final" result
resultDict = json.loads(recognizer.FinalResult())
results.append(resultDict)
textResults.append(resultDict.get("text", ""))
# write results to a file
with open(outfileResults, 'w') as output:
print(json.dumps(results, indent=4), file=output)
self.logMsg("Finished exporting json results file:{}".format(outfileResults))
# write text portion of results to a file
with open(outfileText, 'w') as output:
print(json.dumps(textResults, indent=4), file=output)
self.logMsg("Finished exporting json text file:{}".format(outfileText))
except Exception as e:
messagebox.showinfo("Error Converting mono WAV stereo to json text file", e)
return
root = Tk()
app = Window(root)
root.wm_title("AudioText")
root.geometry("600x600")
root.mainloop()
And Finally…
I hope you find this application useful. If you are interested in generating sound bites/clips from your podcast and transcription file then check out the ClipGenerator application. My next goal is to extract semantic meaning from the transcript file to more easily identify content meaning in the podcast. Stay tuned for more work in this area.
2 comments
Comments are closed.