
This series of posts describes how to convert audio files containing speech to text. This is a Python Vosk Tutorial. In the first post we discussed a number of options for using python to convert speech to text. Given my requirements for open source and local processing I’ve decided to try the Vosk server to perform the speech to text conversion. My ultimate goal is to extract semantic meaning from the text but that will be another set of posts.
The first post in this series discussed various python options for speech to text conversion and why I decided to try Vosk.
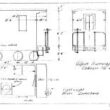
Speech To Text Translation Workflow
This post will describe how to setup the python and Vosk environment for my experiments. Once this environment is in place we will be able to complete the following 3 steps:
- Convert MP3 files to WAV files which is required by Vosk
- Modify 2 channel (stereo) WAV files to 1 channel (mono) also required by Vosk
- Translate WAV file to a json file containing the spoken words
Python Environment Setup
The setup instructions assume a Windows 10 environment. I’m using native python approaches so you should be able to replicate this on Mac/Linux environments without too much change.
Step 1 – create a python installation
Download and install the latest python windows version from python.org which at this time was 3.9.5. If you have an existing python installation it will probably be fine as long as it is 3.x but no guarantees.
Step 2 – create a python environment
I use the venv command to create python virtual environments. To do this in Windows 10 start a command line window and enter the python command shown below. This will create a python virtual environment based on your current python installation. Now you can install python libraries in the virtual environment and keep them away from other python projects you might be working on. Run the command below:
python -m venv C:\Users\xxx\pyenv\NLPOn my system I created a folder call “pyenv” in my user folder (xxx will be your windows userid). I then created a folder called “NLP” for these projects.
Step 3 – activate the NLP python environment
When “venv” created the python virtual environment it created an “activate” batch file. In your command line window run the following command:
cd C:\Users\xxx\pyenv\NLP
C:\Users\xxx\pyenv\NLP\scripts\activate.bat
To make life easier, put the 2 lines above into a batch file “NLP.bat” and save the file to your “c:\users\xxx” folder. This is the folder location initially displayed when you start the command prompt window. Now you can simply open the command prompt window, enter “NLP” and the batch file will change directories to the python environment and run the activate script. At this point you are ready to work.
Step 4 – Create a batch file that starts Idle
Idle is a simple python GUI that ships with python. I will use Idle to run the tutorial python scripts. You can enter the following line at the command prompt to start Idle or you can put this in a file called “idle.bat” and save it to the root of your python environment – C:\Users\xxx\pyenv\NLP\idle.bat
python -m idlelib.idleStep 5 – install 7zip
The FFmpeg libraries and downloaded and installed using the free 7zip program. Here’s the website 7-Zip
Step 6 – install FFmpeg
FFmpeg is a set of API’s that allow you to work with a number of audio formats. My examples include the MP3 format as the original sound file which is a downloaded podcast. You can read more about FFMPEG here – About FFmpeg. The downloads are served from a different page here – I downloaded the following version: ffmpeg-2021-06-19-git-2cf95f2dd9-full_build.7z and unzipped it into the following location (remember xxx is your windows userid) – C:\Users\xxx\AppData\Local\Programs\ffmpeg20210627\
The final step is to add the bin directory to your path environment variable: C:\Users\xxx\AppData\Local\Programs\ffmpeg20210627\bin
Step 7 – Install python libraries
There are two python libraries we need for FFmpeg so run the following commands in your python environment.
Pip install ffmpeg
Pip install pydubpydub is a python library that provides a python api to the FFmpeg functionality. We need all this to convert MP3 files to WAV which will demonstrated in the next post. Here’s a link to some pydub API documentation.
Step 8 – Install Vosk
Vosk is the library that provides the actual speech to text translation software. You can read more about Vosk here. The installation is a bit more tedious than what we’ve done already so here goes.
- download a model from here. I downloaded “vosk-model-en-us-aspire-0.2” which is a large english language model. There are models for multiple languages available. They also have a small english model that you can run on a Raspberry Pi !
- unzip the downloaded model file to a folder named “model”. I put the model folder here… “C:\Users\xxx\pyenv\NLP\model”. The python code will point to the model folder so you can put the model anywhere you want.
- Install the python bindings and vosk dll’s
pip install voskStep 8 – Install Vosk Sample Code
The Vosk sample code is provided in a github repository. This step is optional if you just want to run the scripts I’ve provided but if you want to write you’re own python code it might be worth your time to look at the examples. Clone the github repository which I did using git gui. You can use whatever git methods you are comfortable with. I cloned it to this location – C:\Users\xxx\Documents\vosk- not sure why I put it in the documents folder to be honest but that’s where it is.
Conclusion
Wow – That’s it! This setup will allow you to begin experimenting with Vosk for speech to text translation. In the following post we will present the python code used to complete the first proof of concept with Vosk. In the POC we answer the following “how to” questions:
- convert an MP3 file to a WAV file
- change a stereo WAV file to a mono WAV file
- translate spoken words in a WAV file to a json file containing the words and sentences.
Previous Post – Which Python Library To Use For Speech To Text Conversion
Next Post – How To Convert Speech To Text Using Python and Vosk
The Complete App
If you want to go straight to the full solution then check out this complete python application.
3 comments
Comments are closed.